Intro to HashMap
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key.
理解源码,专注于以下几个方面:
- 理解 Map 相关类似整体结构,尤其是有序数据结构的一些要点。
- 从源码分析 HashMap 的设计和实现要点,理解容量、负载因子等,为什么需要这些参数,如何影响 Map 的性能,实践中如何取舍等。
- 理解树化改造的相关原理和改进原因。
HashMap 源码注释
The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls. This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
HashMap 和 Hashtable 大致等效,除了 HashMap 是非同步的,以及允许空值。无法保证顺序随着时间的推移保持不变。
This implementation provides constant-time performance for the basic operations (get and put),assuming the hash function disperses the elements properly among the buckets.
假设 hash 函数将元素分散在正确的 bucket 中,HashMap 对于基本操作(get 或 put) 会提供常数时间的性能。
何为常数时间 Constant Time
常数时间是表示时间复杂度的一个示例,常见时间复杂度的描述:
| Time complexity | Time description | 时间描述 |
|---|---|---|
| O(1) | Constant time | 常数时间 |
| O(log n) | Logarithmic time | 对数时间 |
| O(n) | Linear time | 线性时间 |
| O(n log n) | Pseudo-linear time | 伪线性时间 |
| O(n^c) | Polynomial time | 多项式时间 |
| O(c^n) | Exponential time | 指数时间 |
| O(n!) | Factorial time | 阶乘时间 |
Iteration over collection views requires time proportional to the “capacity” of the HashMap instance (the number of buckets) plus its size (the number of key-value mappings).
从集合视角看,迭代所需的时间与 HashMap 实例的“容量”( bucket 数量 )及其大小(键-值映射数)成正比。
Thus, it’s very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
因此,如果迭代性能很重要,那么不要将初始容量设置过高(或负载因子设置过低),这很关键。
An instance of HashMap has two parameters that affect its performance:
有两个参数会影响 HashMap 实例的性能:
- initial capacity 初始容量
- load factor 负载因子
The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased.
容量是哈希表中 bucket 的数量,初始容量即是创建哈希表时的容量。负载因子用来评估哈希表填满的程度,以自动增长容量。
When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
当哈希表中的条目数超过负载因子和当前容量的乘积时,哈希表将被重新映射(即内部数据结构将被重建),以使哈希表的 bucket 数大约为两倍。
As a general rule, the default load factor (0.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put).
通常,默认负载因子(0.75)在时间和空间成本之间提供了一个很好的权衡。较高的值会减少空间开销,但会增加查找成本(反应在 HashMap 类的大多数操作中,包括 get 和 put)。
The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations.
设置其初始容量时,应考虑 map 中的预期条目数及其负载因子,以最大程度地减少重新映射操作的次数。
If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
如果初始容量大于最大条目数除以负载因子,则将不会发生任何映射操作。
If many mappings are to be stored in a HashMap instance, creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table.
如果将许多映射关系存储在 HashMap 实例中,创建足够大起始容量的 map 将比让其按需自动增长哈希表重新映射,更有效的存储映射。
Note that using many keys with the same {@code hashCode()} is a sure way to slow down performance of any hash table. To ameliorate impact, when keys are {@link Comparable}, this class may use comparison order among keys to help break ties.
注意,使用许多具有相同 hashcode 的键是降低任何哈希表性能的方法。为了改善影响,当键是 Comparable 时,此类可以使用键之间的比较顺序来帮助打破束缚。
Note that this implementation is not synchronized. If multiple threads access a hash map concurrently, and at least one of the threads modifies the map structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more mappings; merely changing the value associated with a key that an instance already contains is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the map.
注意,这个实现并不是同步的。如果多线程同时访问 hash map,并且至少有一个线程在结构上修改了 map,则必须在外部进行同步。(结构型修改是指增删一个或多个映射关系,更新某个 key 对应的值并不是结构型修改)。通常是对封装 map 的某个对象加同步来实现。
If no such object exists, the map should be “wrapped” using the {@link Collections#synchronizedMap Collections.synchronizedMap} method. This is best done at creation time, to prevent accidental unsynchronized access to the map: Map m = Collections.synchronizedMap(new HashMap(…));
如果没有这样的对象存在,则应该使用 Collections.synchronizedMap 方法来包装 map,最好是在创建时完成,以避免意外不同步地访问 map:Map m = Collections.synchronizedMap(new HashMap(...));
The iterators returned by all of this class’s “collection view methods” are fail-fast: if the map is structurally modified at any time after the iterator is created, in any way except through the iterator’s own remove method, the iterator will throw a {@link ConcurrentModificationException}. Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.
此类的所有“集合视角方法”返回的迭代器都是 fast fail 的:在创建迭代器之后任何时刻对 map 结构进行了修改,除了通过迭代器自已的 remove 方法以外,该迭代器都会抛出 ConcurrentModificationException。因此,面对并发修改,迭代器会快速干净的 fail,而不是在未来的不确定时间冒着任意,不确定行为的风险。
何为 fast fail
Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the presence of unsynchronized concurrent modification. Fail-fast iterators throw ConcurrentModificationException on a best-effort basis. Therefore, it would be wrong to write a program that depended on this exception for its correctness: the fail-fast behavior of iterators should be used only to detect bugs.
注意不能保证迭代器的 fast fail 行为,一般来说,在存在不同步的并发修改情况下,不可能作出任何严格的保证。因此,编写依赖于此异常的程序的正确性是错误的:迭代器的 fast fail 行为仅用于错误检测。
This class is a member of the Java Collections Framework
Map 的整体结构
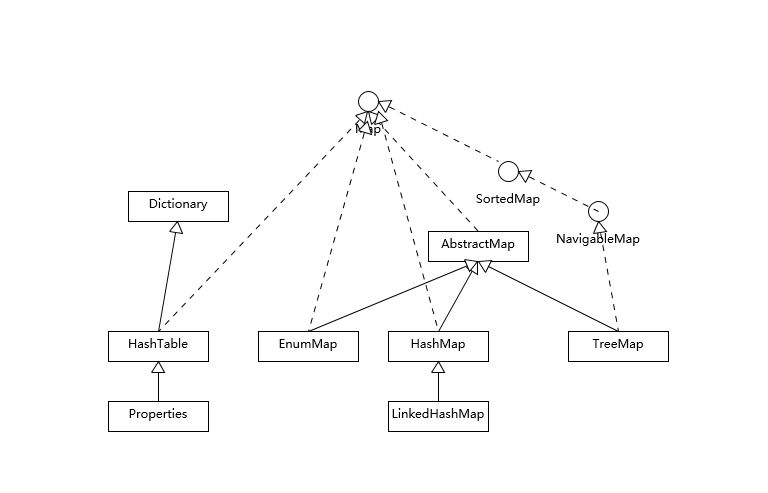
HashMap 等其他 Map 实现都扩展了 AbstractMap,大部分 Map 的使用场景,就是 put、get 或者 remove,而对顺序没有特别的要求,HashMap 在这种情况下就是最优选择。对顺序有要求的情况,可以选择 LinkedHashMap 和 TreeMap,两者的实现非常不同。
LinkedHashMap 通常提供的是遍历顺序符合插入顺序,它的实现是通过为键值对维护一个双向链表。通过特定的构造函数,我们可以创建反映访问顺序的实例,如 put、get、compute 等,都算作“访问”。
如我们构建一个空间占用敏感的资源池,希望可以自动将最不常访问的对象释放掉,可以利用 LinkedHashMap 提供的机制来实现:
public class AutoCleanMapSample {
public static void main(String[] args) {
LinkedHashMap<String, String> accessOrderedMap = new LinkedHashMap<String, String>(16, 0.75F, true){
@Override
protected boolean removeEldestEntry(Map.Entry<String, String> eldest) {
// 实现自定义删除策略,否则行为就和普遍Map没有区别
return size() > 3;
}
};
}
}
对于 TreeMap,它的整体顺序是由 key 的顺序关系决定的,通过 Comparator 或 Comparable 来决定。
HashMap 源码实现
主要围绕几个问题来进行
- HashMap 内部实现基本点分析
- 容量(capacity)和负载系数(load factor)
- 树化
HashMap 的内部结构
HashMap 在 JDK 7 和 JDK 8 的底层实现是不一样的,在 JDK 7 中,HashMap 使用的是数组 + 链表实现的,JDK 8 中使用的是数组+链表或红黑树实现。
JDK 7 中的实现如图:
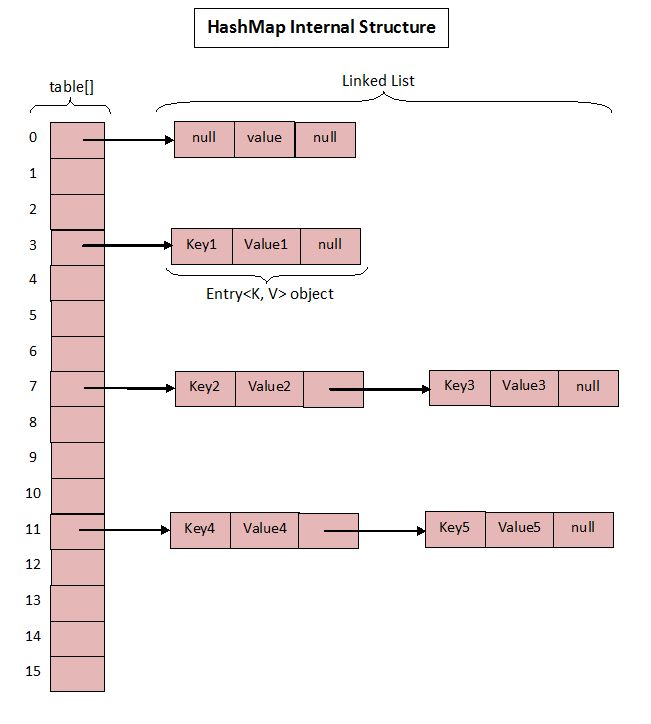
HashMap 可以看作是数组(Node<K,V> table)和链表结合组成的复合结构,数组被分为一个个 bucket,通过 hashcode 决定了键值对在这个数组的寻址;hashcode 相同的键值对,以链表的形式存储。
每个 Node 包含的内容为:
static class Node<K,V> implements Map.Entry<K,V> {
// hashcode of key
final int hash;
final K key;
V value;
// next node
Node<K,V> next;
}
HashMap 插入流程
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// table 为 null 时,resize 负责初始化 table(lazy-load:第一次 putVal 时才初始化 table)
n = (tab = resize()).length;
// Node 在 table 内的位置取决于 (n - 1) & hash
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 大于 TREEIFY_THRESHOLD(8),且 size 大于 64 时链表转换红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
// resize 负责扩容
resize();
afterNodeInsertion(evict);
return null;
}
仔细观察 putVal 方法入参 hash 的源头会发现,它并不是 key 本身的 hashcode,而是来自 HashMap 内部的一个 hash 方法。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>>16;
}
为何这里需要将高位数据移位到低位进行异或远算呢?
这种方式能避免只取低位进行计算的结果,通常我们的n都不会很大,如果直接拿hashcode的值,那么高位的哈希值其实是没有参与进来的;这样将自己的高位与低于异或,其实是混合了高低位,变相了保留了高位的信息,以此来加大低位的随机性
HashMap 扩容流程
final Node<K,V>[] resize() {
// ...
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACIY &&
oldCap >= DEFAULT_INITIAL_CAPAITY)
newThr = oldThr << 1; // double there
// ...
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPAITY;
// 以默认值计算 threshold
newThr = (int)(DEFAULT_LOAD_FACTOR* DEFAULT_INITIAL_CAPACITY;
}
if (newThr == 0) {
// threshold = capacity x load factor
float ft = (float)newCap * loadFator;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);
}
threshold = neThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newap];
table = n;
// 移动到新的数组结构e数组结构
}
观察源码,我们可以得到要点:
- threshold = capacity x loadFactor,如果构造 HashMap 时未指定这两个值,那么就以默认值计算
- threshold 通常以倍数进行调整(newThr = oldThr « 1),根据 putVal 中的逻辑,当元素个数超过 threshold 大小时,则扩容(resize)。
- 扩容后,需要将老的数组中的元素重新放到新的数组,这是扩容的一个主要开销来源
Capacity、Load Factor 和 Treeify
为什么需要在乎 capacity 和 loadFactor 呢,因为这两个值直接决定了可用 bucket 的数量,空的 bucket 太多会浪费空间,如果使用的太满则会影响操作性能。假设极端情况下,只有一个 bucket,那么它就退化成了链表,完全不能提供所谓常数时间(Constant Time)的性能。
treeify 对应的逻辑自 putVal 和 treeifyBin 中
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//树化改造逻辑
}
}
上面精简的 treeify 方法,可以理解为,当 bin 的数量大于 TREEIFY_THRESHOLD 时:
- 如果容量小于 MIN_TREEIFY_CAPACITY,会进行扩容
- 如果容量大于 MIN_TREEIFY_CAPACITY,会进行树化改造
那么 HashMap 为什么要树化呢?
本质这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都会放置到一个桶里,则会形成一个链表,我们知道链表查询是线性的 O(n),会影响存取性能。
而在现实世界,构造哈希冲突的数据并不是非常负责的事情,恶意代码就可以利用这些数据大量与服务端交互,导致服务端 CPU 大量占用,这就构成了哈希碰撞拒绝服务攻击。
Java8 的 HashMap 的数据存储是链表+红黑树的组合,如果数据量小于 64 则只有链表,如果数据量大于 64,且某个桶链表的数据量大于8,那么该处会转换为红黑树。 红黑树的插入、删除、查找各种操作性能都比较稳定。哈希碰撞频繁,导致链表过长,查询时间陡升,黑客则会利用这个『漏洞』来攻击服务器,让服务器CPU被大量占用,从而引起了安全问题。 而树化(使用红黑树)能将时间复杂度降到对数时间 O(logn),从而避免查询时间过长。